機械学習の手法のうち「線形回帰」について。
目次
AI・ディープラーニングの全体像
- 人工知能
- 機械学習
- ディープラーニングの基本・応用
- ディープラーニングの研究
- AIプロジェクト
- AI社会実装に伴う法律・倫理
機械学習(教師あり学習)の手法①線形回帰
概要
- 「線形回帰」とは、1つ以上の「説明変数」と「線形関数」を使用し、連続値である「目的変数」を予測する手法
- 「目的変数」とは、予測したい値(ゴール)
- 「説明変数」とは、目的変数を説明する予測の手がかりとなる変数(特徴量とほぼ同じ)
- 「線形回帰」→「単回帰分析」「重回帰分析」
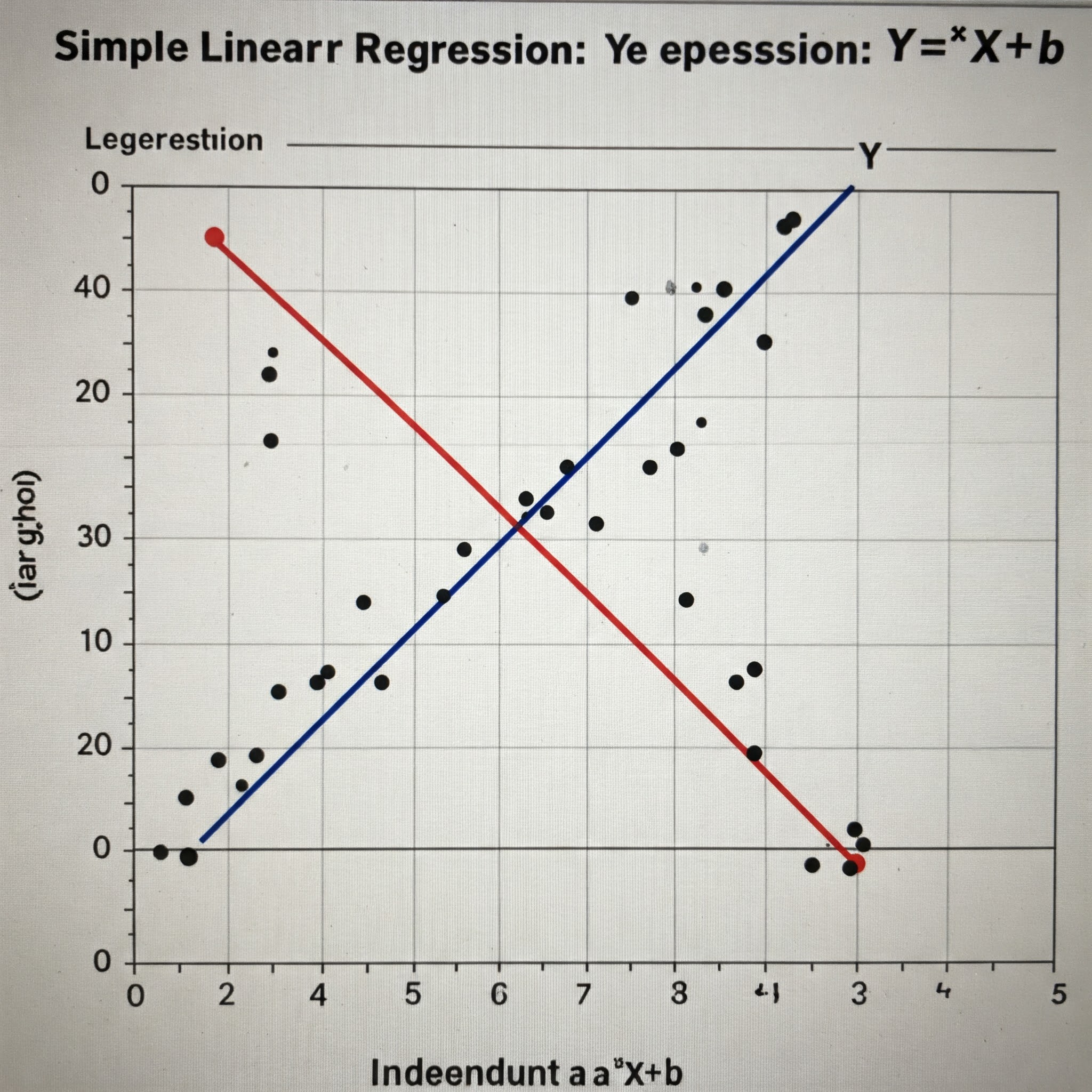
単回帰分析
- 「単回帰分析」とは、「説明変数が1つだけある線形回帰」
- Y=a*X+b
※Y:目的変数(ゴール)
※X:説明変数
※a:回帰係数(傾き)、説明変数Xの「影響度」
※b:回帰係数(切片、オフセット)、スタート - 分布に、直線を当てはめて、分布の特徴を表現できる傾きaと切片bを定め、単回帰モデルを導出する
- aとbが定まった後、未知のデータをXに代入することで、予測値Yを得ることができる
重回帰分析
- 「重回帰分析」とは、「説明変数が複数ある線形回帰」(複数の説明変数から目的変数を予測する)
- Y=a1*X1+a2*X2+…+an*Xn+b
※ai(i=1,2,…,n):偏回帰係数(各説明変数の予測したい量への影響度) - 偏回帰変数の大小を比較することで、”どの変数が予測に重要なのか”という目安が分かる
- 「多重共線性(Multicollinearity)」→相関が高い説明変数同士を特徴量として組み合わせた際に、互いに干渉してしまい、精度が悪くなってしまう現象
- 変数同士の相関係数を計算し、相関係数が「1または-1」に近い場合、相関が高いといえる
正則化
- 「正則化(Regularization)」→過学習を防ぐための対策
- 学習の指標である「損失関数」「誤差関数」に、オフセット値である「ペナルティ項(罰則項)」を追加する
- 「損失関数」→モデルの予測出力と正解の誤差を表す関数であり、最小化するよう学習していく
- モデルを表すグラフの形が大きく触れると、損失関数も高次元になりがちになり、過学習しやすくなる
→回帰係数の値が大きい状態と解釈される
→回帰係数の大きさを抑えるために、「損失関数」に「ペナルティ項」を加え、全体を最小化する
→モデルが訓練データに過剰に合わせ込まれることを防ぐ効果がある(正則化) - 「ペナルティ項」→係数の大きさ(ノルム)を用いて定義
- E(w)
※w:回帰係数のベクトル - 正則化を行わない場合は、E(w)のみを最小化するようパラメータを学習
- 正則化を行う場合、「損失関数」と「ペナルティ項」の和を最小化する
- E(w) + λ(1/p)Σ|wi|^p
※λ(1/p)Σ|wi|^p:ペナルティ項であり、係数の絶対値p乗和の形
※λ:ペナルティの重さを制御する役割(大きくすると過学習に陥りにくいが、学習不足になる)
| L1正則化 | ・p=1(パラメータの絶対値の和)をペナルティ項にする ・不要なパラメータを削ぎ落とし、特徴選択と次元圧縮に効果を出す ・「ラッソ回帰(Lasso Regression)」 |
|---|---|
| L2正則化 | ・p=2(パラメータの二乗和)をペナルティ項にする ・パラメータの大きさをゼロに近づけ(影響を抑え)、汎用性の高い滑らかなモデルが得られ、過学習防止に効果を出す ・リッジ回帰(Ridge Regression)」 |
※「Elastic Net」→ラッソ回帰とリッジ回帰を組み合わせた手法